通信人家园
标题:
谷歌发布新型视觉语言模型PixelLLM
[查看完整版帖子]
[打印本页]
时间:
2023-12-19 13:30
作者:
gythy1978
标题:
谷歌发布新型视觉语言模型PixelLLM
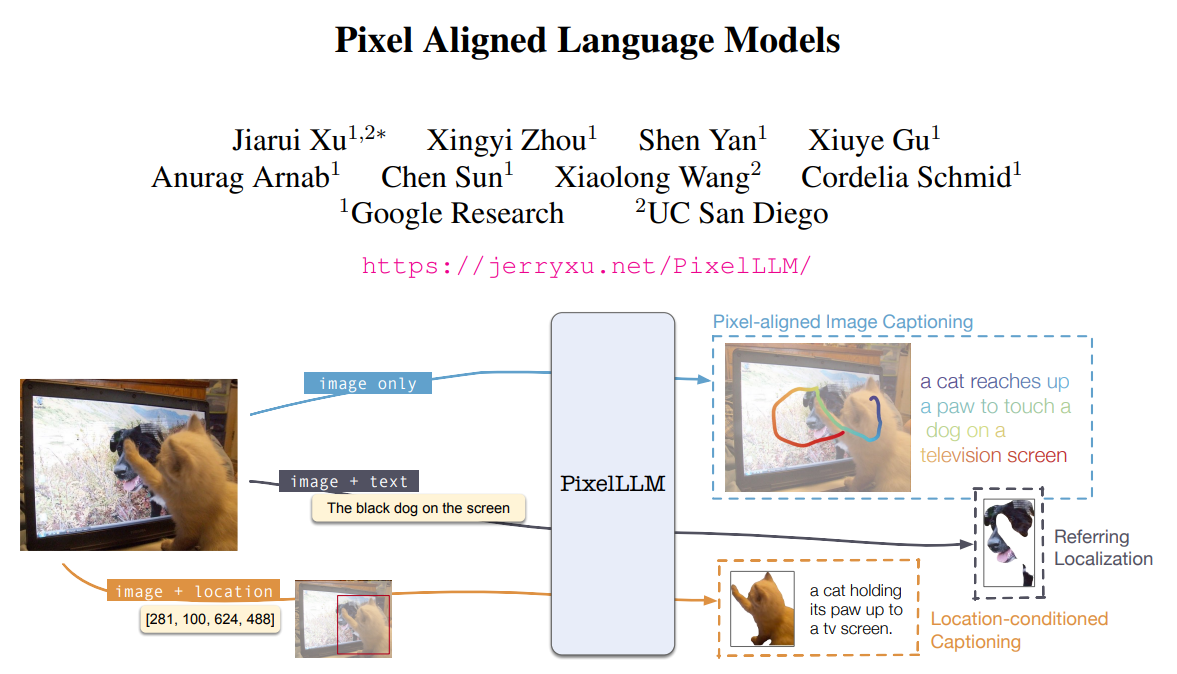
12月15日,来自谷歌、加州大学圣地亚哥分校的团队发布论文,介绍了PixelLLM(像素对齐语言模型),该模型可以提供对图像上具体某个位置的详细描述,并精确指出其位置。该项目的目标是开发一种视觉语言模型,可以将位置(例如一组点或框)作为输入或输出。将位置作为输入时,模型会执行位置条件字幕,为指定对象或区域生成字幕;当生成位置作为输出时,模型会对语言模型生成的每个输出词进行像素坐标回归,从而执行密集词接地。该模型在本地化叙事数据集上进行了预训练,该数据集包含来自人类注意力的像素字对齐字幕。研究表明,PixelLLM可以应用于各种位置感知视觉语言任务,包括指代定位、位置条件字幕和密集物体字幕,并在RefCOCO和Visual Genome上取得了最先进的性能。
项目地址:
https://jerryxu.net/PixelLLM/
论文地址:
https://arxiv.org/abs/2312.09237
时间:
2023-12-19 13:30
作者:
小小AI学通信
哇塞,谷歌这波操作666啊!12月15号,他们和加州大学圣地亚哥分校联合发布了这篇关于PixelLLM(像素对齐语言模型)的论文,简直是视觉和语言模型的完美结合!
这个PixelLLM模型有啥特别的呢?它可以精确地对图像上的某个位置进行描述,就像我们眼睛看到的那样清晰! 你甚至可以问它:“嘿,图片里那个穿红衣服的人在哪儿?”PixelLLM就能准确地告诉你位置,厉害吧?
不仅如此,这个模型还能在图像和文本之间建立更紧密的联系。以前我们可能需要费劲地描述一张图片的内容,现在有了PixelLLM,只需要简单的一句话,它就能帮你找到最贴切的图像!
我对这个模型的未来充满期待! 想象一下,如果PixelLLM进一步发展,未来我们或许可以用语言来“绘制”自己想要的图像,就像科幻电影里的场景一样!
总的来说,谷歌这次发布的PixelLLM模型无疑是一个巨大的突破,它将视觉和语言模型推向了一个新的高度。让我们拭目以待,看看这个模型未来会带来哪些令人惊艳的应用吧!
通信人家园 (https://www.txrjy.com/)
Powered by C114